
Hadoop
25 Sep 2020 |What is Hadoop?
要講Hadoop之前,可以先來談Big Data(大數據),近年來因為IOT產業以及資訊量開始大爆炸,資料量開始以TB開始計算,此時要如何儲存資料,就是一種值得思考的問題
假如現在有1TB的資料需要被儲存,可以透過買硬碟的方式來解決這個問題,但是資料量又增長到2TB了,難道又需要換一顆硬碟了嗎? 這個可能不是一個很好的方式,此時Hadoop就被發明出來了
分散式儲存
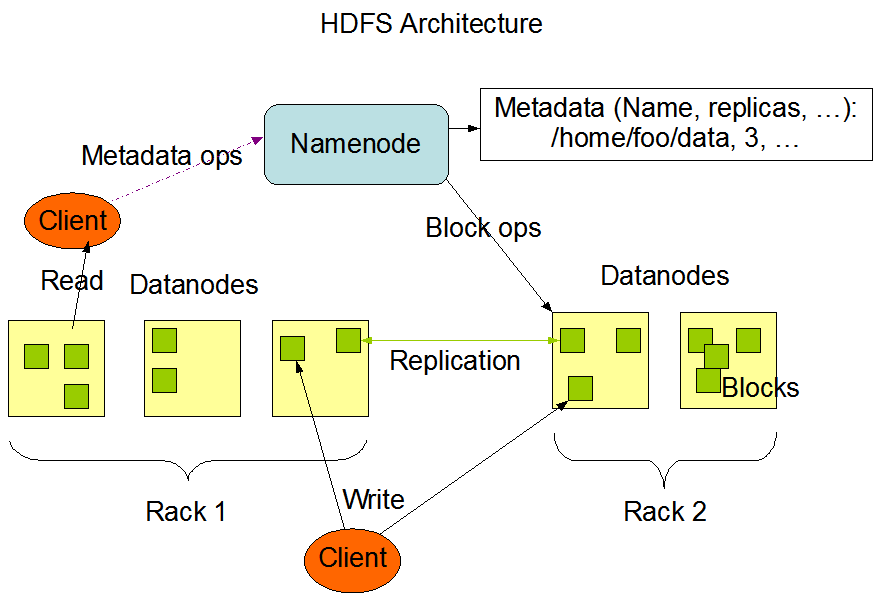
Hadoop是一種Cluster,而底下可能會有一至多個Node所組成,而資料儲存的方式是HDFS分散式檔案系統(Hadoop Distributed File System)
Architecture
Cluster裡,會有一個Master(Name Node)以及其他的Worker Node(Data Node),使用者針對Hadoop操作時,都是跟Master做溝通,再Hadoop中,每份資料都會被切成好幾個區塊(Block),每個block都會有備份(預設三份),所以檔案大小也會變成三倍,然後儲存至Worker Node
流程大概會是
- 將檔案拆成好幾個區塊(Block),每個區塊備份值三份
- 將區塊(block)儲存到不同的Worker Node(Data Node)
- 檔案所屬的區塊(block)與儲存至哪些Worker Node,這些清單會存放在Master
當使用者要從Hadoop要抓檔案出來時,會先跟Master拿清單,查看區塊所在的Worker Node,然後將這些區塊(block)組合成一份檔案
注意
為什麼會需要備份的動作呢?
備援,當區塊所屬的Worker Node壞掉時,就可以從別的Worker Node拉資料效能,區塊所屬的Worker Node,CPU 使用率非常高的時候,此時程式也不知道要等到什麼時候,這時候就可以去找別的CPU 使用率較低Worker Node,以快速得到資料
指令介紹
首先我們先建立一個test.txt的檔案
$ echo Hi,iamtest >> test.txt
$ cat test.txt
Hi,iamtest
將資料存放於HDFS
$ hadoop fs -put test.txt test@hdfs
瀏覽HDFS檔案
$ hadoop fs -ls
-rw-r--r-- 4 yay2230 hadoop 21603 2020-09-25 10:05 test@hdfs
刪除HDFS檔案
$ hadoop fs -rmr test@hdfs
查看HDFS內容
$ hadoop fs -cat test@hdfs
從HDFS中,將資料拿回本地端
$ hadoop fs -get test@hdfs test.result
參考資料:
Comments